
A question our sales team often gets from potentials customers is: “How many hosts/services can I monitor with a single Nagios XI license?” As much as we’d like to be able to give people a concrete answer to the question, it ultimately comes down to either “We don’t know,” or “That depends on….”. So as a side project, I decided to attempt my second benchmark test with Nagios XI, and see how hard we can push the software, having learned a few things since my first test almost a year ago. Most of my findings from that first test were outlined in the document Maximizing Nagios XI Performance. Since writing this, we’ve learned a few tricks from both Core and XI users that have been done in larger environments, and we’ve also played with a few ideas we’d never tried before. So here’s the rundown on what we’re using for a test machine, the tweaks I tried, and the results I found. Special thanks to Nagios Community members Daniel Wittenberg, Jeff Sly, Nate Broderick, and Max Schubert for your large installation tips.
Nagios XI Server (An older physical desktop we converted to a test machine).
- Intel Dual Core CPU 3gz
- 2gb of RAM
- 140gb HD, probably 7200 RPM
- Offloaded MySQL to a VM with 1gb of RAM, and a single CPU
- 823 Hosts, 3379 Services. All active checks running on a 5mn check interval.
- 4200 checks in 5mn
- 14 checks per second on average
- All active checks are being executed from the XI server, mostly running PING, HTTP, DNS To IP, and DNS Resolution
The Results:
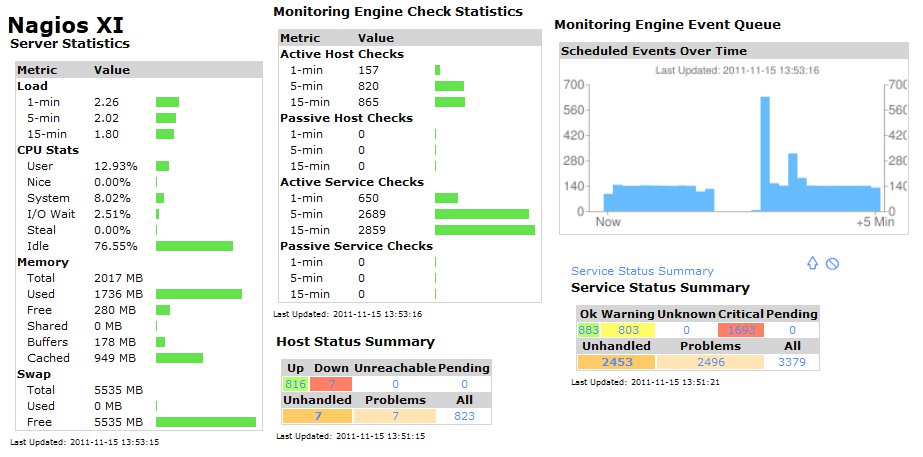

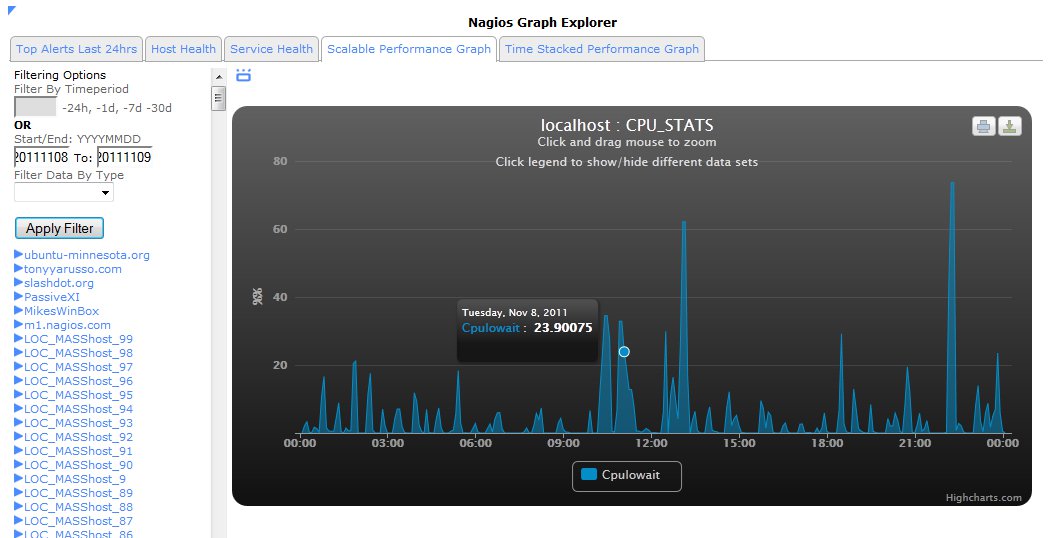
The CPU load generally hovers around a comfortable 1.75 to 2.5, and the real page load times for the XI interface range from about 1-7 seconds, depending on the page. Below is a list of tweaks that I found actually made a noticeable impact on the server’s performance
- #1 effect on peformance by far, offloading MySQL to a second server. This cut the CPU load to less than half.
- Utilizing a RAM Disk for status.dat, objects.cache, host-perfdata, and service-perfdata to reduce disk I/O
- Using rrdcached to reduce disk writes from performance data
- Avoid use of active SNMP, and check_esx3.pl checks as much as possible
- Used the following settings for MySQL caching, as recommended by Jeff Sly, added to /etc/my.cnf:
-
12345678910##experimental DB tweakstmp_table_size=524288000max_heap_table_size=524288000table_cache=768set-variable=max_connections=100wait_timeout=7800query_cache_size=12582912query_cache_limit=80000thread_cache_size=4join_buffer_size=128k
- Added the following hourly cron job:
-
1234567#!/bin/shntpdate pool.ntp.org/sbin/service httpd restart/sbin/service postgresql restartpsql nagiosxi nagiosxi -c "vacuum;"psql nagiosxi nagiosxi -c "vacuum analyze;"psql nagiosxi nagiosxi -c "vacuum full;"
- I also did some experimental tweaks to the nagios init script to enable faster startup options. However, I don’t recommend this for production environments unless you know how to manage a custom init script, and my shell scripting is still sketchy enough that I had some problems with multiple nagios instances being spawned because of this. But the reason I enabled this is that I wanted Nagios to restart itself once per hour to level off the check schedule, since I noticed that after a while the checks get scheduled unevenly, causing CPU spikes at some times, and valleys at others.
- In the Admin->Performance Settings page, I changed the “Dashlet Refresh Multiplier” to 2000, used all unified dashlet options, and set all of the DB tables to delete information that would be older than 2 weeks. I found that keeping the database tables trimmed tightly kept everything running faster. I did increase the refresh date of the dashlets that gave performance information for the XI server so that I could see all of the server statistics in a fairly up-to-date manner.
- I also spent a LOT of time staring at filtered results from “top” ; )
The next stage of our benchmark testing will be to offload the checks themselves to slave machines using either DNX or Mod Gearman to distribute the check load. We’re also going to upgrade our benchmark box once more, so my hope is to to able to load a single XI instance to 20-30k checks every 5 minutes, but I’m sure we’ll discover our share of new complications and bottlenecks as we continue to scale XI to a larger install. We’ll keep you posted on what you find! If you have suggestions for further tweaking an XI install, post a comment because we’d love to hear them!
 Our team is excited that Nagios was just awarded
Our team is excited that Nagios was just awarded  W00t! SecTools.org has released their list of top 125 security tools and Nagios is
W00t! SecTools.org has released their list of top 125 security tools and Nagios is 










